Tesla AI Day 01

2021년 8월 20일에 발표된 테슬라 자율주행 기술 세미나
비전 기반으로 자율주행을 진행하는 테슬라의 초기 기술과 문제점을 제시한다.
Tesla Vision
raw data를 프로세싱하는 nn 디자인

- 원시데이터가 스택으로 들어와 nn 처리를 통해 벡터 공간화되는 사진 → 벡터공간의 일부 정보를 렌더링해서 차량의 스크린에 보여줌
- 8대의 카메라로부터 데이터 들어옴 → nn → vector space 로 실시간 옮기는 처리 수행
- vector space: 운전 시 필요한 정보-도로의 커브, 신호등, 교통 표지판 등 3차원으로 표현
- nn 구성 과정
- nn의 역할: 인간의 시각을 통해 얻는 정보 - 카메라를 통해 얻은 정보 처리하여 주변 환경 인식
1. raw data 받아서 nn으로 전달
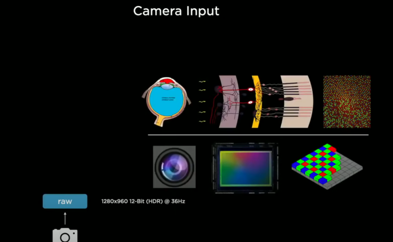
- 빛이 인공망막에 닿게 되면 프로세스 시작됨
2. RegNet
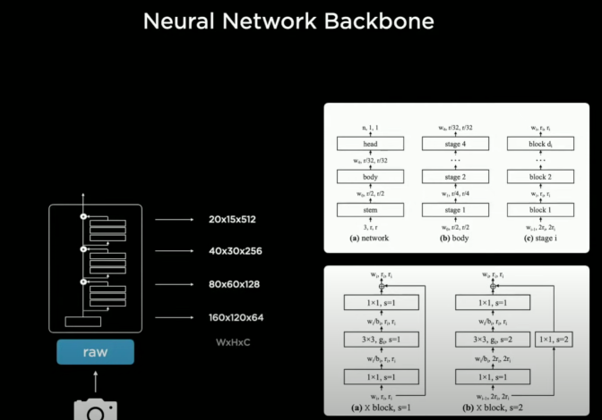
- input image: 가로 1280x 세로 960, HDR(high dinamic range), 12-bit 인코딩, 36 FPS로 영상 입력됨
- nn의 feature extractor(특징을 찾아내 의미있는 데이터를 식별하는 과정)를 구체화하는 backbone으로 ResNet(Residual Neural Network) 이용: 그 이미지의 데이터의 특징을 찾아, 의미있는 데이터 구분하여 구체화 함.
- 많은 residual block 이 서로 연결된 stem 이 있음 ⇒ RegNet
- RegNet
- residual block이 서로 연결되어 있고, 이 연결성을 효과적으로 구현하기 위해 사용
- nn를 위한 좋은 디자인 공간을 만듦
- latency와 acc의 trade-off 할 수 있도록 지원
- regnet의 output: 서로 다른 해상도와 스케일의 feature 추출 (W x H x C)
- 고해상도는 적은 채널을, 저해상도는 많은 채널을 가지도록 설계됨
- backbone이 깊어질수록 고 → 저해상도로 압축 이루어짐
- 입력과 가까운 layer; 디테일 - 먼 layer; 전체 맥락
- residual block이 서로 연결되어 있고, 이 연결성을 효과적으로 구현하기 위해 사용
3. BiFPN
- feature pyramid network(FPN)로 regnet을 프로세싱 함. 이것을 BiFPN이라고 함.
- BiFPN: multi-scale feature pyramid fusion을 위함 - 다양한 해상도를 이용한 방법을 통해 각 feature들이 서로 효과적으로 정보를 공유할 수 있음
- 디테일한 정보를 인식할 수 있는 layer에서 전체영역으로 보았을 때 이 인식한 물체가 차인지 아닌지 확인하는데 사용
- ex) 도로에 조그마한 patch가 있다고 했을 때, 위쪽에서 넓게보고있는 애가 아래쪽 애한테 “지금 고속도로 끝 부분에 있어서 잘 안보이는건데(vanishing point), 저건 차야” 라고 말해주면서 희미하게 보였던 물체가 자동차라는 것을 식별하는 데 도움을 줌.
4. task specific heads
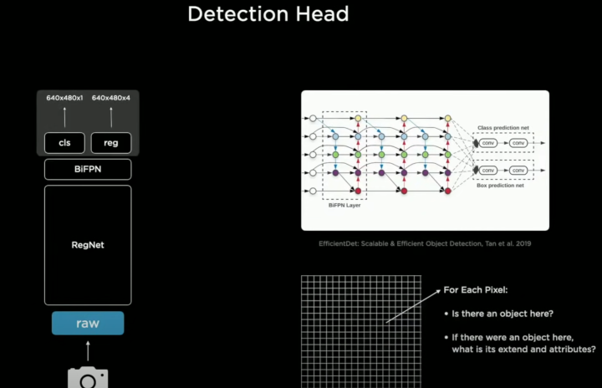
- YOLO와 같은 object detection 과정 거침
- Detection Head; 비트맵 이미지 상에서 물체의 존재여부 & 물체의 영역 및 속성을 추정하는 목적 → 특정 task에 대한 detection 가능
- cls(classification): binary형태, 그 픽셀을 기준으로 물체의 존재 유무 나타냄 - 1개의 채널에 그 값 저장
- 래스터(비트맵 이미지) 초기화 → 저기에 차가 있는지 아닌지를 알려주는 해당 위치별 binary bit가 존재
- reg(regression): cls에 값이 있을 때 그 값 기준으로 x,y축으로의 길이, 그 물체에 대한 속성값 4개의 채널에 저장
- 차가 있는게 맞다면, 다른 여러가지 특징 고려; xy축 너비와 높이, offset 등 차인지 아닌지를 구분하기 위한 여러 특징
- (여기까지가 detector가 스스로 인식하는 과정) 이제 하나의 차량만 인식하는 게 아니고 매우 많은 작업을 해야 함. → 신호등 감지하고 인식하고 차선 예측하는 등
- cls(classification): binary형태, 그 픽셀을 기준으로 물체의 존재 유무 나타냄 - 1개의 채널에 그 값 저장
5. multi-task learning “HydraNets”
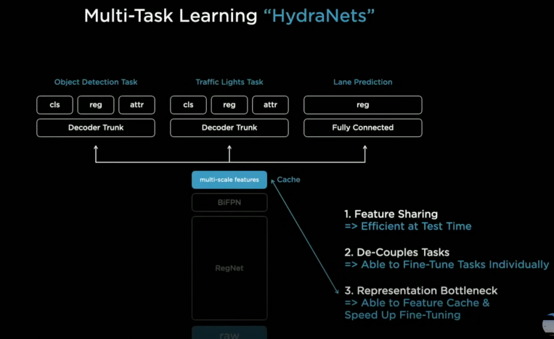
- 1개의 backbone의 출력을 이용해 다양한 task(object detection, traffic light task, lane prediction task)
- 48개의 backbone networks와 대략 1000개의 아웃풋으로 구성
- 3가지 이점
- feature를 서로 공유: 계산량과 추론과정이 줄어들어 효율적
- de-couples tasks: backbone이후 각 task마다 연결 구조 끊을 수 있어서 독립적으로 작업 수행 가능
- 특정 head를 통해 추가 데이터셋 사용- fine tuning
- representation bottleneck
- backbone 매번 학습하지 x
- 출력부인 multi-scale feature부분 fine tuning
- features에 대한 병목현상 생김 → 보통 이 특징들을 디스크 캐쉬에 저장해놓음 → workflow를 fine-tuning할때 캐쉬된 특징 중에 골라낸 head만을 튜닝함
- end-to-end로 쭉 돌리고, 멀티 스케일 레벨의 특징들을 캐쉬에 저장함 → fine tuning → 다시 end-to-end training
Results
1. hydra-net
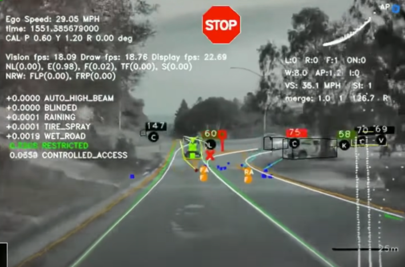
- 이미지를 각각 독립적으로 프로세싱하는 version
- 한계: FSD가 제대로 작동하기 위해서는 이것만으로는 충분치가 x → smart summon 공부
2. smart summon 공부
- 차량을 호출한 주인을 찾기위해 커브 인식 → 이미지 공간 예측만으로는 직접 주행을 할 수 x → 차량 주변을 벡터공간으로 구성해야만 함.
- “occupancy tracker” 개발: 이미지로부터 커브를 인식해내고, 카메라별 역역에 대한 장면 계속해서 stitching
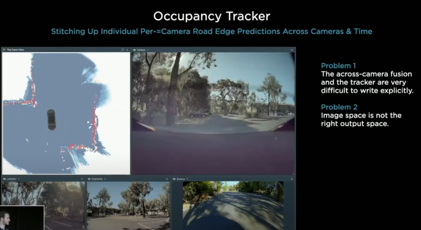
- 2가지 한계
- occupancy tracker 튜닝과 hyper-parameter가 엄청 복잡
- C++로 수작업하는 것은 불가능, nn을 통해 training시켜야 함
- 이미지 공간이 실제 공간이 아니라는 점 → 이미지 공간이 아닌 벡터 공간을 바로 만들어야 함
- occupancy tracker 튜닝과 hyper-parameter가 엄청 복잡

- 한계-현상: 이미지 공간상에서는 잘 예측하는것으로 보이나, 벡터 공간으로 옮기고 나면 엉망이 되어버림
- 원인: 픽셀별로 정확한 깊이를 예측할 수 없기 때문, 공간으로 인식된게 아니기 때문에 가려진 부분을 예측하는 것도 불가능
3. 사물인식의 또 다른 문제

- 카메라로만 예측하게 된다면, 한 대의 차량이 8개의 카메라에서 5개의 차량으로 보여졌을 때 문제 발생
- multiple images를 하나의 뉴럴넷에 동시에 보냄 → 벡터공간으로 바로 옮겨가도록 함
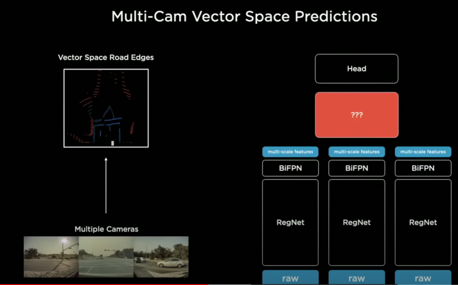
- 위 네트워크의 한계 2가지
- image space → vector space로의 변환작업을 수행할 nn을 어떻게 만들것인가?
- nn에서 벡터공간을 예측하려면, 벡터공간의 데이터셋이 있어야만 함
- 벡터공간 레이블링 필요
Tesla AI Day 02에서는 위에서 제시한 한계를 해결하여 오직 비전만으로 자율주행을 가능하게 한 테슬라의 기술을 소개합니다.
Continue with AI Day 02
해당 포스트는 아래를 참고하여 작성되었습니다.