Tesla AI Day 02

2021년 8월 20일에 발표된 테슬라 자율주행 기술 세미나
오직 비전만으로 자율주행을 가능하게 한 테슬라의 기술을 소개한다.
<Tesla AI Day 01에서 제시한 초기 기술의 한계를 해결하기 위한 방법>
1. nn 아키텍처에 집중
- bird’s-eye view(조감도): 새가 하늘에서 내려다보듯 땅의 기복을 표현한 지도
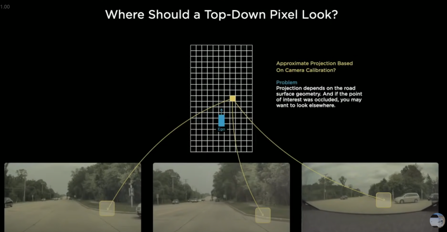
- ex) 그림에서, 노란 픽셀이 도로 커브의 일부인지 아닌지 판단하려는 예시
- 이런 종류의 예측을 가능하게 하는것은 이미지 공간 어디로부터 오나?
- 해당 포인트를 카메라 이미지에 개략적으로 표시할 수는 있음
- 한계: 이 projection이 정확하게 이루어지기는 어려움
- 도로면의 선형측면 때문
- 도로면 경사가 오르막 or 내리막 일수도 있음
- 데이터 때문에 발생할수도 있음- 다른 차가 저 부분을 가로막을 수 있음
- → transformer
2. transformer
![]()
- multi-head self attention을 사용하기 때문에, 보이지 않는 부분에 대한 예측을 가능하게 함
- 과정
- 원하는 output space의 사이즈만큼 래스터 이미지 초기화
- output space에서 sin, cos 함수를 이용해 위치정보 인코딩 o
- MLP와 함께 query vector 속으로 인코딩
- 모든 이미지와 그 특징은 고유의 key, value 나타냄
- key, value에 대한 query가 multi-head self attention으로 들어옴
- → 모든 이미지 조각이 각각의 key를 브로드캐스팅하는 활동이 효과적으로 시작됨
- key: 나는 필러의 일부분인데, 대충 이 정도 위치에서 이런것들을 보고있어
- 관련있는 모든 query들: 나는 output space 현재 위치에 있는 픽셀인데, 나는 이런 종류의 특징이 필요해
- → key와 query들이 상승적으로 상호작용함 → 값 제대로 추출 가능
- → 공간 표현 o, 변환 효과적으로 가능하게 함
- 구현 디테일
![]()
- 차량에 있는 카메라들은 살짝씩 서로 다르게 각도가 삐뚤어져 있음 → 이미지 공간 → output space로 변환시, 카메라 calibration 고려 o
- 모든 이미지의 카메라 calibration 정보 연결 → MLP로 보냄
- 이때, 모든 이미지를 특수한 수정 변환 과정을 거쳐서 합성된 가상 카메라로 변환하는 것이 효과적
- Rectify layer; 카메라 calibration 기능
- 모든 이미지를 일반적인 virtual camera로 전환시킴
- blur한 카메라 이미지를 → 또렷하게 나타낼 수 있음
- 결과
![]()
- 한계: 매 순간마다 완전히 독립적으로 작동
![]()
- 전후관계 맥락에 따른 정보만 가지고 예측해야 하는 상황 多
- → 비디오 모듈 넣자
3. video module
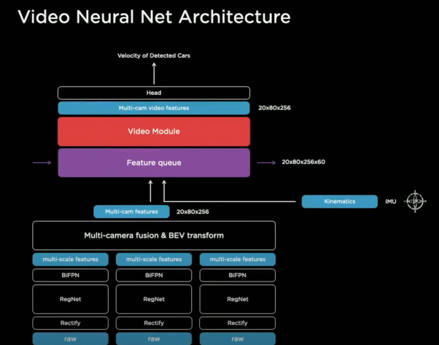
- 예전 비디오를 이용한 multi-scale feature를 계속해서 캐쉬화하는 feature cue 모듈을 nn에 집어넣음
- 비디오 모듈; 이 정보들 일시적으로 섞어서 사용
- heads; 계속해서 디코딩
- 모듈
- kinematics: 차가 어떻게 움직이는지를 알려주는 속도, 가속도에 대한 것, 예전 카메라로부터 어떻게 주행했고, 현재 차량은 어떻게 주행하는지 알 수 있음
- feature que
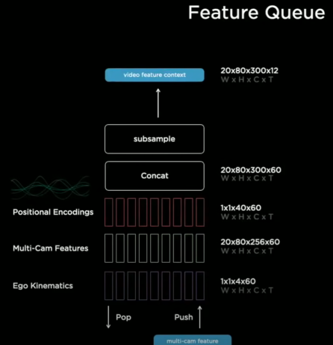
- kinematics(차량의 운동정보) & 위치정보 인코딩 & feature 등을 서로 연결시킴 → 인코딩 → feature que에 저장 → 비디오 모듈
- pop & push
- feature que의 관점에서 que에게 push 보내고자 할때, 시간을 base로 하는 que 이용하려 함
- 다른 차량이 일시적으로 환경을 가리면, nn은 과거 레퍼런스 메모리 자료에서 비슷한 경우를 찾아서 볼 수 있는 능력이 생김
- “이건 지금 뭔가 가려진 것 같은데, 과거 특징들 찾아서 여전히 잘 인식할 수 있어!”
- 도로지형, 구조 미리 예측하고자 할때
- “나는 좌회전 차로이고, 옆 차는 직진 차로이지” 미리 알아야 할 때가 있음.
- 시간베이스 que만을 사용하게 된다면, 적색신호에서 기다리는 동안 features를 잊어버릴수도 있음 → 공간베이스 que도 사용
- features를 캐쉬하고, 계속해서 비디오 모듈에 보내주는 역할 하는 시공간베이스 que 사용
- feature que의 관점에서 que에게 push 보내고자 할때, 시간을 base로 하는 que 이용하려 함
- 비디오 모듈 종류
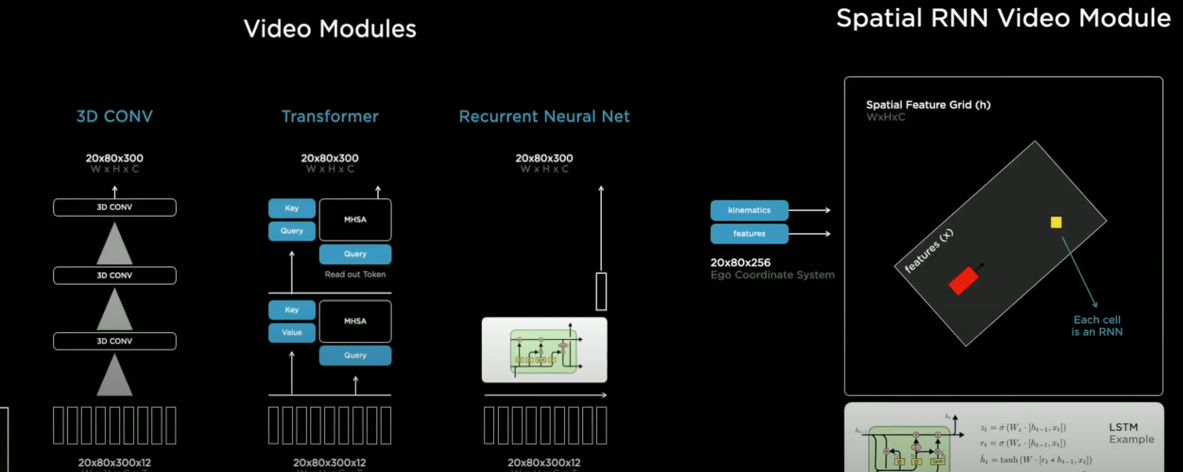
- spatial recurrent neural network 비디오 모듈에 주목
- 구조적 문제 때문에, 2차원 표면에서 주행함 → hidden state를 2차원 격자위에 체계화 함
- 주행하다가 차량 주변에 보이기 시작하는 부분만 업데이트
- 주행 시, 차량위치와 숨겨진 features를 통합시키기위해 kinematics 사용
- 차량 가까운 곳이 보이기 시작할 때 RNN 업데이트
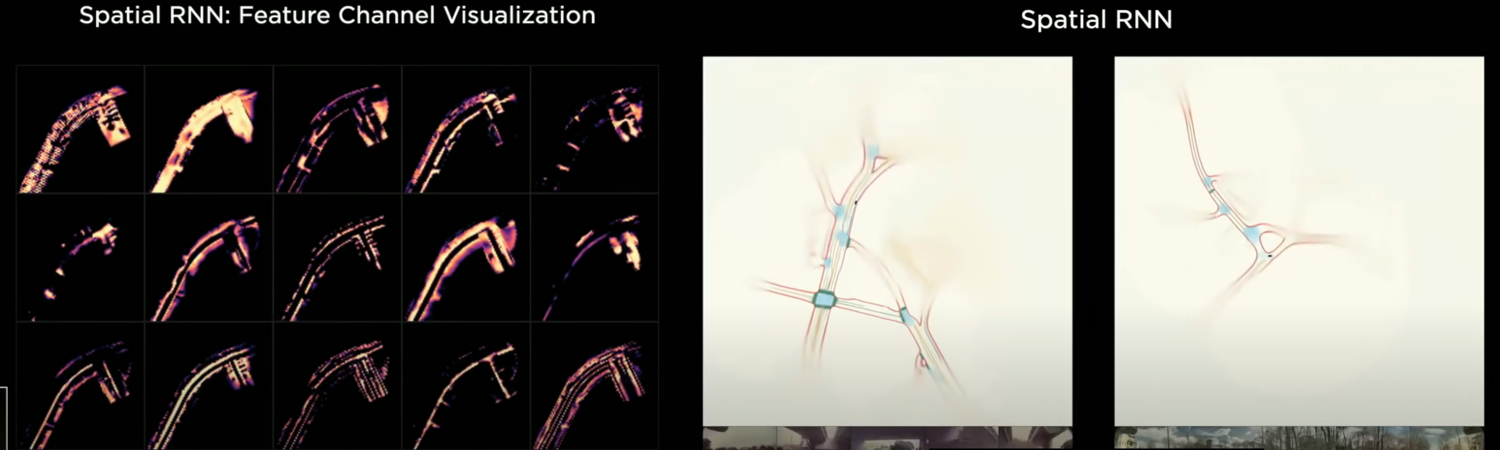
- hidden state of RNN
- nn이 메모리에서 선택적으로 읽고 쓸 수 있는 능력이 생김을 알 수 있음
- ex) 어떤 차가 내 옆을 가려서 잠시동안 도로의 일부가 보이지 않더라도, nn은 그 위치를 메모리에 저장하지 않는 능력이 생긴것 → 그 차가 떠나고 나면 잘 보이게 되니까!
전체 네트워크 정리
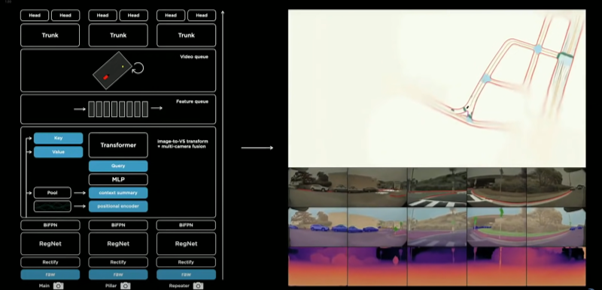
- 원시이미지
- rectification layer; camera calibration 위해 → common virtual camera
- regnet, residual network; 서로 다른 스케일의 많은 feature로 프로세싱
- BiFPN; multi-scale 정보 융합
- transformer; output vector space로 옮겨짐
- 시공간 feature que로 보내짐
- spatial RNN과 같은 비디오 모듈에 의해 프로세싱됨
- 계속해서 다른 작업들을 위한 trunk와 head등과 함께 hydranet에서 구조화 진행
- 개선사항
- nn관점에서, 시공간 fusion이 좀 느림 → bottom 쪽 network인 cost volume or optical flow 수행
- output: 조밀한 이미지 형태인 래스터 → 이걸 차량에서 처리하기에는 자원이 많이 소모됨
- latency 줄여야 함
- point by point 방식 연구; 도로 구조를 드문드문 인식하는 방안
Continue with BEV Former
해당 포스트는 아래를 참고하여 작성되었습니다.