Adversarial Attack
Adversarial Attack 공부내용정리와 프로젝트, 그리고 논문작성까지 정리한 페이지
Adversarial Attack의 개념과 방어기법을 살펴보고, 해당 공격에 영향을 받지 않는 robust(강인한) 모델을 직접 구현해보며 연구를 진행한다.
Advseraial Attack 개념

Goodfellow et al. “Explaining and harnessing adversarial examples.”
적대적 공격이란 딥러닝을 이용한 모델에 적대적 섭동(adversarial perturbation)을 적용하여 오분류를 발생시키는 것을 말한다. 섭동은 모델의 예측 오류를 최대로 만드는 방향으로 모델 입력값을 최적화하면서 형성되고, 육안으로는 구분하기 어려울 정도로 작고 미세하게 나타난다. 이런 섭동이 더해진 입력 값을 적대적 예제(adversarial example)라고 한다.
Adversarial Attack 방어기법
- Survey — adversarial attack 방어기법에 대한 논문 서베이
- Robust Superpixel-Guided Attentional Adversarial Attack — 관심있게 읽었던 논문 발표 자료
Adversarial Attack에 대해 강인한 모델 구축 프로젝트
- FakeCheck — Deepfake 탐지모델 강화 및 애플리케이션
ACK2022 논문 게재 승인
S. Lee, J.-H. Hou*, “Improving the Robustness of Deepfake Detection Models Against Adversarial Attacks”, in Korea Information Processing Society ACK, 2022 (논문경진대회 은상)
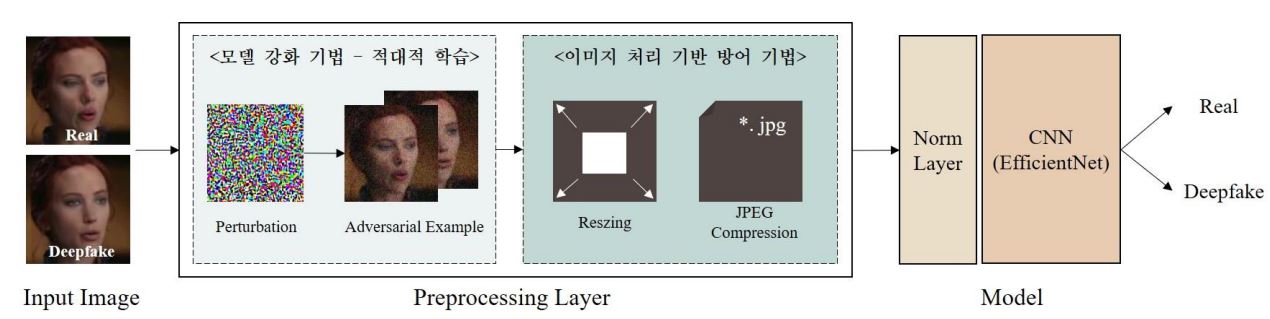
제안하는 모델 아키텍처
딥페이크(deepfake)는 딥러닝(Deep Learning)과 페이크(fake)의 합성어로, 딥페이크로 인한 디지털 범죄는 날로 교묘해지면서 사회적으로 큰 파장을 불러일으키고 있다. 이때, 딥러닝 기반 모델의 오류를 발생시키는 적대적 공격(adversarial attack)의 등장으로 딥 페이크를 탐지하는 모델의 취약성이 증가하고 있고, 이는 매우 치명적인 결과를 초래한다.
본 프로젝트에서는 2 가지 방법을 통해 적대적 공격에도 영향을 받지 않는 강인한(robust) 모델을 구축하는 것을 목표로 한다. 모델 강화 기법인 적대적 학습(adversarial training)과 영상처리 기반 방어 기법인 크기 변환(resizing), JPEG 압축을 통해 적대적 공격에 대한 강인성을 보였다.